










Le dernier document de recherche de Flare article présente une nouvelle approche de l'intelligence artificielle (IA), où la combinaison de l'IA et de la blockchain conduit à une IA plus sûre et plus précise.
L'apprentissage par consensus permet une IA collaborative dans un large éventail d'applications, ce qui permet de développer des modèles d'IA plus précis et plus robustes. L'apprentissage par consensus est particulièrement adapté à l'intégration de l'IA dans les secteurs sensibles aux données, tels que les soins de santé ou la finance, améliorant ainsi les processus de prise de décision et renforçant la performance et l'efficacité opérationnelles globales, ce qui peut se traduire par une baisse du coût des services pour le consommateur final. Il peut en résulter des résultats nettement meilleurs pour les patients, une analyse financière plus précise ou une meilleure détection des fraudes, entre autres avantages. Contrairement à la plupart des implémentations existantes de l'IA et de la blockchain, qui permettent l'accès à l'apprentissage automatique centralisé (ML) par le biais de la blockchain, CL tire parti de la blockchain pour créer des modèles d'IA décentralisés.
Motivations
Ces dernières années, l'accent a été mis de plus en plus sur les environnements distribués, dans lesquels les données et les ressources informatiques sont réparties sur plusieurs appareils. Cette évolution est motivée par les exigences des modèles de fondation modernes, tels que les grands modèles de langage et les modèles de vision par ordinateur, qui requièrent des quantités substantielles de données à traiter. Dans cet environnement distribué mais toujours centralisé, la décentralisation apparaît comme un besoin fondamental, motivé par plusieurs raisons essentielles.
Les méthodes centralisées présentent des risques inhérents au fait qu'elles reposent sur une seule partie de confiance, ce qui limite leur utilisation principalement à une seule entreprise et freine leur adoption à plus grande échelle. En outre, ces architectures augmentent non seulement la vulnérabilité aux attaques potentielles ou aux défaillances du système, mais soulèvent également des inquiétudes quant à la confidentialité et à la sécurité des données. À l'inverse, les méthodes décentralisées présentent un avantage certain : elles permettent aux utilisateurs de développer des modèles locaux personnalisés, adaptés à leurs exigences et préférences spécifiques, alors que les approches centralisées manquent souvent de la flexibilité nécessaire à une telle personnalisation. Face à ces limites, l'apprentissage par consensus apparaît comme une solution de ML décentralisée offrant plus de résilience, de confidentialité et d'adaptabilité, tout en atténuant les risques inhérents à la centralisation.
Avantages de l'apprentissage par consensus
Les protocoles de consensus sont essentiels à la sécurité des registres décentralisés et protègent les réseaux de blockchain contre les attaques malveillantes. L'exploitation des mécanismes de consensus pour l'IA présente de nombreux avantages, parmi lesquels nous soulignons les suivants :
- Des performances accrues. Les méthodes CL bénéficient des données de chacun des contributeurs de l'ensemble, ce qui réduit les biais et améliore la capacité des modèles à généraliser sur des données inédites. La CL peut également conduire à une IA plus précise que les méthodes centralisées, principalement en raison de la capacité de la blockchain à encourager la collaboration, ce qui conduit à une plus grande compétence dans la combinaison de diverses idées provenant de divers modèles. Cela se fait par le biais de multiples agrégations locales, où chaque participant évalue les prédictions des modèles voisins et les intègre pour une meilleure précision. C'est l'un des premiers cas où l'IA peut tirer des avantages significatifs de l'intégration de la blockchain.
- Sécurité. En présence d'acteurs malveillants tentant d'introduire des objectifs cachés, l'intégrité des modèles CL reste intacte grâce aux caractéristiques de sécurité intégrées des mécanismes de consensus. Cela garantit que les systèmes d'IA s'abstiennent de générer des prédictions délibérément nuisibles ou des inexactitudes involontaires, qui sont toutes deux des caractéristiques de l'IA malveillante. Par conséquent, CL répond à une préoccupation majeure de la communauté de l'IA, à savoir la protection de l'IA contre l'exploitation à des fins préjudiciables. En préservant l'intégrité du processus d'apprentissage collaboratif, CL inspire une plus grande confiance dans les systèmes d'IA, ouvrant ainsi la voie à leur déploiement responsable et éthique.
- Confidentialité des données. Dans CL, ni les données sous-jacentes des participants au réseau ni leurs modèles individuels ne sont partagés à aucun moment. En fait, il n'y a pas d'attaques malveillantes sur le réseau capables de compromettre la confidentialité des données, puisque celles-ci restent stockées localement. La préservation de la confidentialité n'encourage pas seulement la collaboration, mais préserve également la compétitivité. À cet égard, CL permet la monétisation des données grâce à l'IA, en particulier pour les données sensibles ou commerciales telles que les soins de santé, ce qui permet de surmonter les difficultés rencontrées précédemment dans les environnements centralisés.
- Décentralisation totale. Les données et les ressources de calcul sont réparties sur un réseau de participants, qui communiquent sans dépendre d'un seul serveur central. La nécessité de la décentralisation est bien visible dans les applications modernes de ML en raison de la demande de grandes quantités de ressources et de la complexité croissante des modèles de ML. La ML décentralisée apparaît comme une solution plus appropriée pour préserver la confidentialité des données et garantir la sécurité.
- Efficacité. Le processus d'apprentissage présente une faible latence et nécessite beaucoup moins de temps de calcul, d'énergie et de ressources que d'autres méthodes de ML décentralisées de pointe. La méthode CL est donc particulièrement adaptée aux applications en temps réel, où la rapidité de la prise de décision et l'efficacité de l'utilisation des ressources sont primordiales.
Comment cela fonctionne-t-il ?
L'apprentissage par consensus améliore les méthodes d'ensemble grâce à une phase de communication, au cours de laquelle les participants partagent leurs résultats (modèles) jusqu'à ce qu'ils parviennent à un accord. L'apprentissage par consensus est un processus en deux étapes qui peut être mis en œuvre comme suit :
- Phase d'apprentissage individuel. Chaque participant au réseau développe son propre modèle, sur la base de ses données privées et d'autres données accessibles au public. Cela peut aller de la construction d'un modèle à partir de zéro à l'utilisation de grands modèles pré-entraînés et à leur adaptation à leurs besoins. Il est important de noter qu'il ne sera jamais demandé aux participants de partager des informations sensibles sur leurs données ou leur modèle. Une fois l'entraînement terminé, les participants prépareront leurs prédictions initiales pour un ensemble de données de test - il peut s'agir d'un ensemble de données divulgué par le biais d'un contrat intelligent ou, alternativement, les participants peuvent proposer de nouveaux points de données de test par le biais d'un mécanisme Proof-of-Stake, par exemple.
- Phase de communication. Les participants transmettent leurs prédictions initiales au sein du réseau selon un protocole de consensus/gossip. Au cours de ces échanges, les participants mettent continuellement à jour leurs prédictions afin de refléter les évaluations des autres participants au réseau, ainsi que la confiance dans leurs propres prédictions. En outre, un participant peut contrôler la qualité des prédictions reçues du reste du réseau et s'en servir pour améliorer sa prise de décision. À la fin de cette phase, les participants se mettent d'accord ("consensus") sur la décision jugée optimale compte tenu des informations disponibles au sein du réseau. Cette phase est ensuite répétée pour toute nouvelle entrée de données.
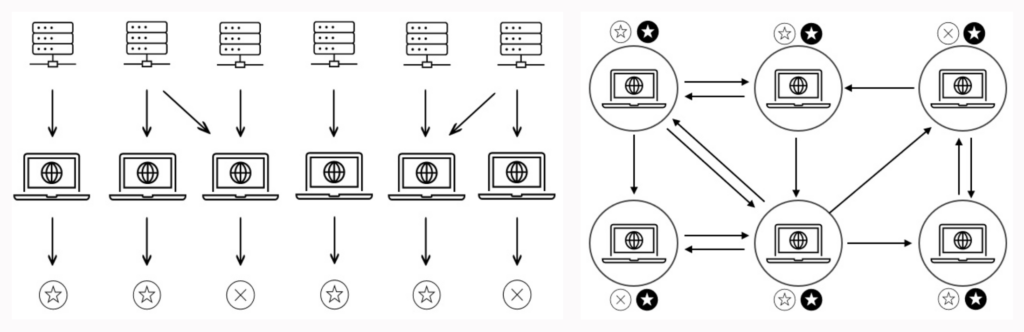
Légende de la figure: Exemple de fonctionnement du CL pour une tâche de classification binaire. (a ) Au cours de la première étape, les participants développent leurs propres modèles, sur la base de leurs propres données et éventuellement d'autres données volontairement partagées par d'autres participants. À la fin de cette phase, chaque modèle détermine une prédiction initiale (représentée par les cercles creux) pour toutes les entrées de l'ensemble de données de test. (b) Dans la phase de communication, les participants échangent et mettent à jour leurs prédictions initiales, pour finalement parvenir à un consensus sur une sortie unique (représentée par les cercles pleins). Cette phase est répétée pour toute nouvelle entrée de données.
Strictement parlant, l'algorithme décrit ci-dessus se réfère à un scénario de ML supervisé - plus précisément, il s'agit d'un cadre dans lequel les ensembles de données d'apprentissage sont déjà étiquetés et où l'algorithme fait des prédictions pour les étiquettes de nouvelles données de test non vues. Toutefois, la méthode CL peut également être adaptée aux problèmes de ML auto-supervisée ou non supervisée, où les participants n'ont accès qu'à des données partiellement ou totalement non étiquetées. Les objectifs de ces méthodes sont légèrement différents, ce qui oblige les participants à utiliser des techniques différentes au cours de la phase d'apprentissage individuel. Néanmoins, la phase de communication se déroulerait de manière similaire à la description fournie ci-dessus.
Comment l'apprentissage par consensus se distingue-t-il ?
L'idée qui sous-tend CL est de combiner efficacement les connaissances (sous forme de modèles d'IA) provenant de sources multiples sans partager d'informations sensibles ou précieuses ou de propriété intellectuelle. Cette approche est conçue pour protéger les informations confidentielles, tout en garantissant la résilience contre les risques potentiels posés par des entités malveillantes. CL s'appuie sur le paradigme très réussi de l'apprentissage d'ensemble, qui fournit des techniques puissantes pour fusionner plusieurs modèles en un seul. Les méthodes d'ensemble reposent sur le principe de la "sagesse des foules", qui consiste à tirer parti de la connaissance collective d'une foule pour surpasser celle d'un seul de ses membres.
Plusieurs implémentations de services d'IA sur la blockchain ont vu le jour ces dernières années, mettant en avant des approches innovantes pour intégrer l'IA dans les réseaux décentralisés. Par exemple, Bittensor facilite les inférences de l'IA (sortie de modèle) au sein de ses sous-réseaux spécifiques à un domaine, en pondérant les prédictions des "mineurs" grâce à un mécanisme de théorie des jeux. FLock.io offre une plateforme d'apprentissage fédéré (un type différent d'apprentissage distribué), bien qu'avec un agrégateur centralisé, utilisant la blockchain pour valider les mises à jour de modèles et récompenser les participants. Un autre exemple est Ritual, qui exploite efficacement une place de marché pour les modèles ML grâce à son protocole Infernet, où les demandes d'exécution d'un modèle spécifique sont envoyées au propriétaire du modèle.
CL se distingue par sa méthode d'agrégation distincte, dans laquelle les prédictions des modèles individuels passent par un protocole de commérage sécurisé afin de parvenir à un accord. Ainsi, CL exploite la blockchain pour créer des modèles d'IA décentralisés, alors que les implémentations existantes permettent d'accéder à des ML centralisés par le biais de la blockchain. L'objectif est de permettre une IA plus précise et plus sûre grâce à la collaboration, tout en permettant aux entités qui détiennent des données privées, souvent sensibles, de rejoindre le système, tout en garantissant la confidentialité de leurs données.
En résumé
L'apprentissage par consensus offre une opportunité inédite de mettre en œuvre l'apprentissage automatique directement sur des registres décentralisés tels que les blockchains. Avec cette initiative, nous assistons à l'émergence d'une nouvelle approche dans laquelle la technologie de la blockchain peut fondamentalement améliorer les outils d'intelligence artificielle existants. Cela ouvre des possibilités passionnantes d'innovation et de collaboration sécurisée dans des secteurs traditionnellement sensibles aux données, tels que les soins de santé, ouvrant la voie à l'adoption de techniques d'apprentissage automatique collaboratives. En outre, la résilience des méthodes de ML face à des facteurs malveillants favorise une plus grande confiance dans les systèmes d'IA, renforçant leur fiabilité et leur intégrité.